今天pycon第二天~看到許多年輕的工程師與強者,深深覺得在看不到地方,也有很多熱情的工程師默默為整個社會提供穩定厚實的技術力量,想到就覺很興奮,自己也要好好好努力!
上章前提說明,第一點提到Q-table皆會取最大值,我們來花點篇幅說明這個值是什麼。
想像你是神奇寶貝大師小智,當下正在state1(平靜的皮卡丘),首先,你會知道有哪些動作可執行:action1(捏臉)跟action2(摸頭),接著你把state1跟兩個動作分別輸入取值,Q(state1,action1)跟Q(state1,action2),分別得到-3跟5,則最大值為5。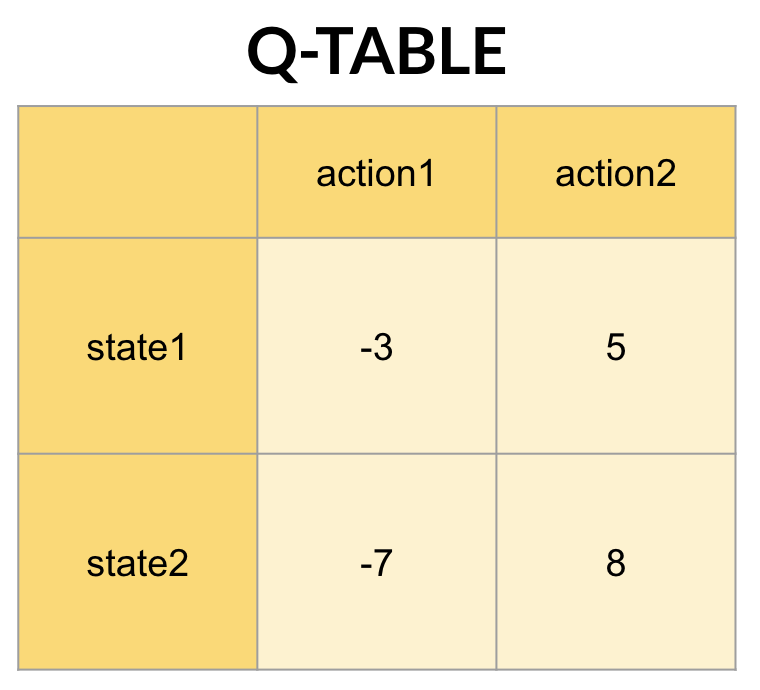
Q-table取值過程沒問題,但值是什麼?Q-估計得到的值,除預測當下的獎懲(reward),還要加上下一步的max-value(最大值獎勵)。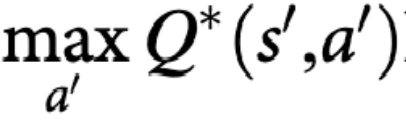
到這邊可能會有點感覺,如果我是加下步(sate2,action')最大值,那下步也是預測當下獎勵與下下步(action'')最大值,最終展開如下: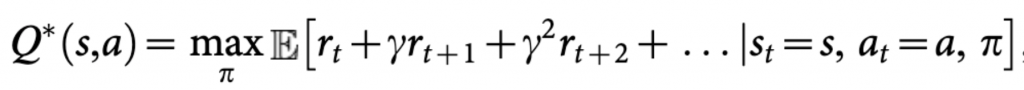
到這應該就一目了然了嘛!Q-learning的值就是估計所有連續state最大值總和。
γ 在這代表著衰減值,位於0~1之間。常常像有人說,人生如戲,戲如人生,假設你的人生就是場遊戲好了,你活著會希望這輩子的體驗值是max的。你希望30歲進google,當然除google外你還有其他選擇,例如facebook、群暉或亞馬遜...但假設30歲進google對你滿足度最大。
我們再設個條件,當下的你十六歲,十六歲的你會覺進google很重要?當然重要,但當下應該先唸好書、上煎好大學、取得大公司的實習機會或合作計畫。儘管每個階段都有max值,但越遠reward的對當下的Q估計越不重要。所以state越遠,γ 的指數越大,對當下state來說就越不重要。
所以當你想擁有幸福美滿的人生,讓每個階段滿足感max就對哩。當然精彩不亮麗,起落是無常,就算前面走錯路,下個階段action還是可取max值。Q-learning表現出種積極樂觀性,但這種特性同樣會帶來些麻煩,這個未來會做講解。
我們以兩個端值做講解:
Q估計的值這邊講完了,在了解真正值代表什麼與γ後,明天就來介紹怎麼做Q-learning的學習囉XD

